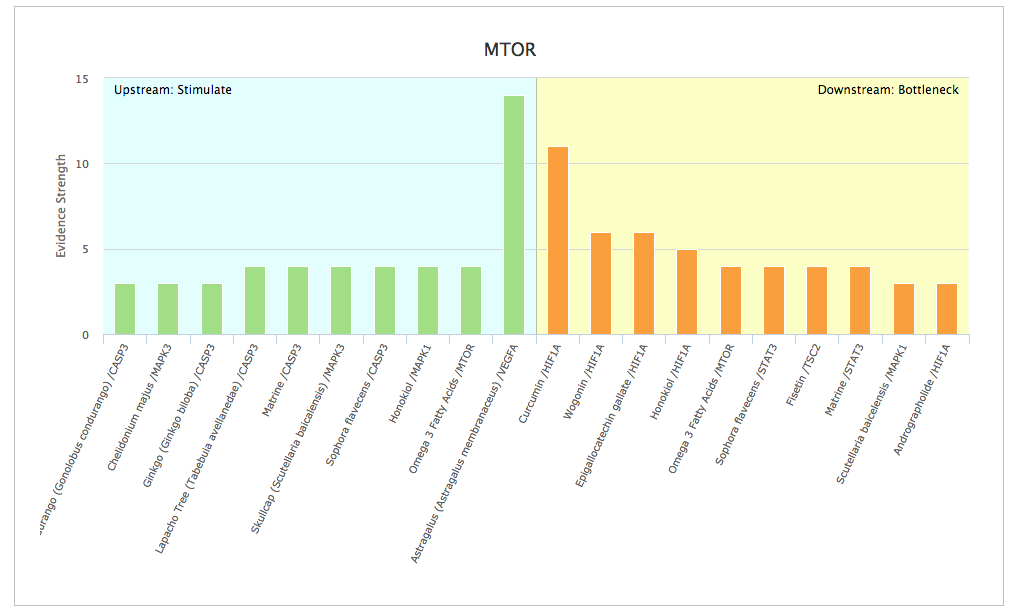
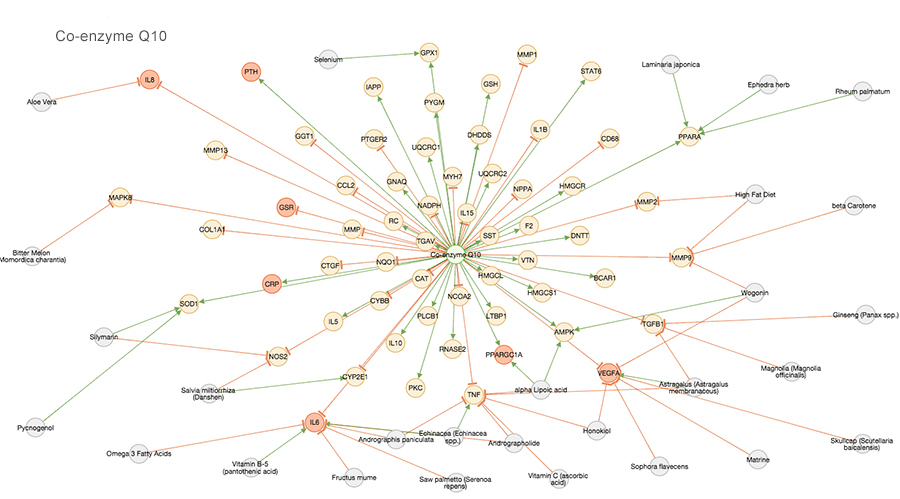
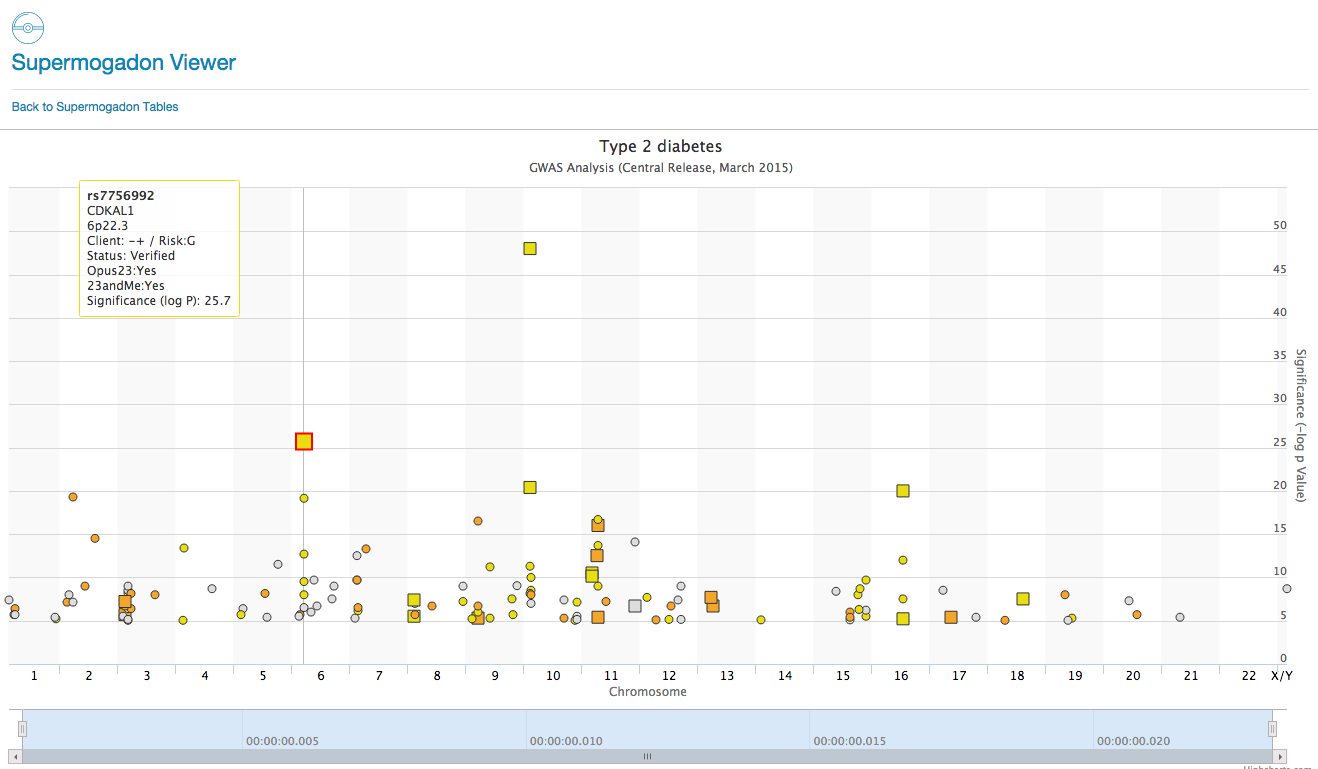
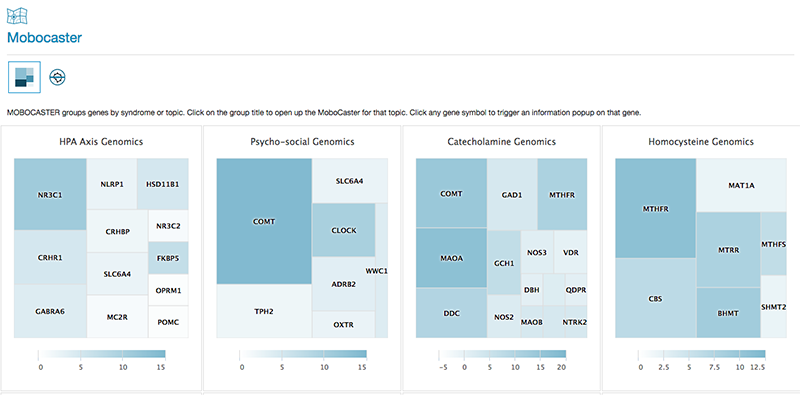
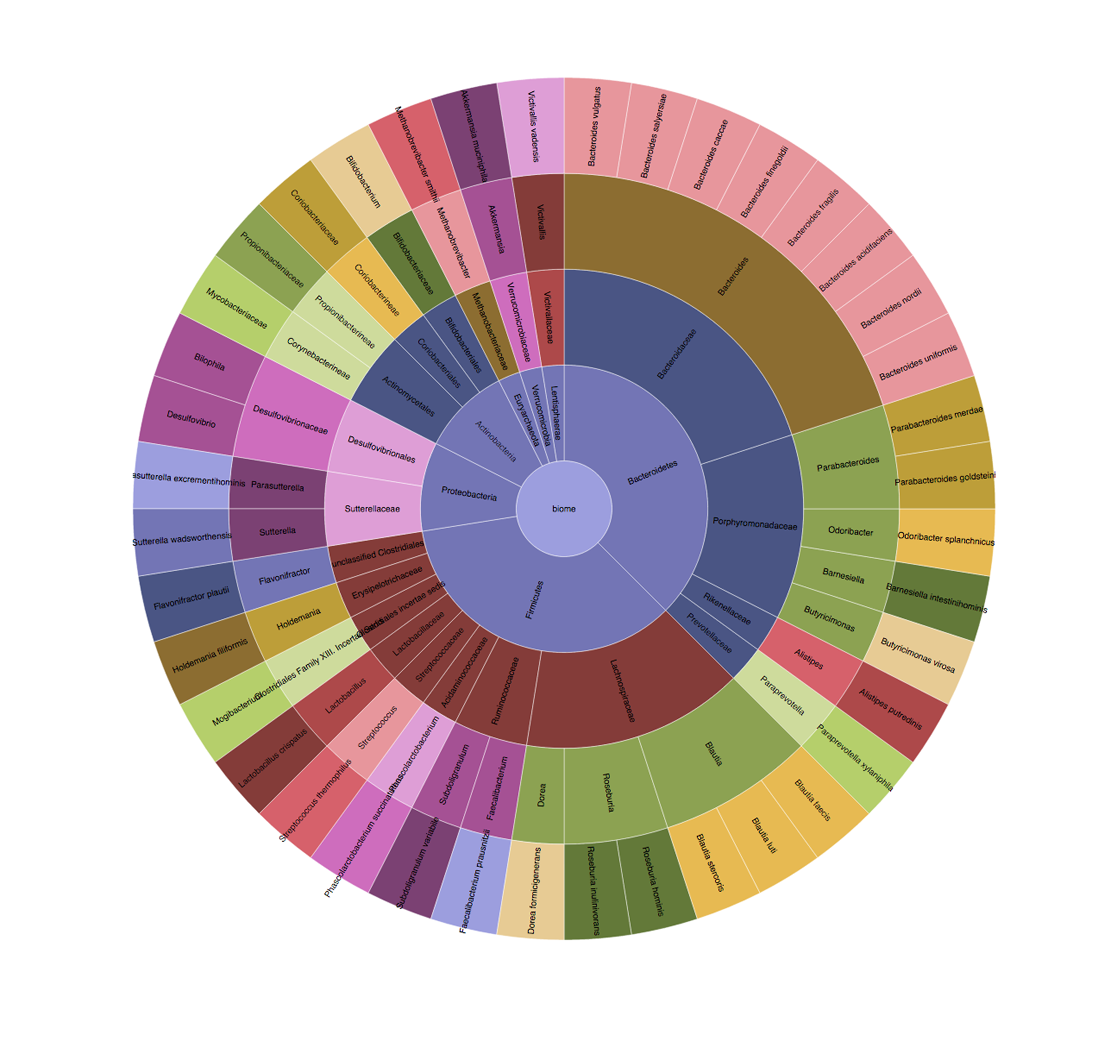
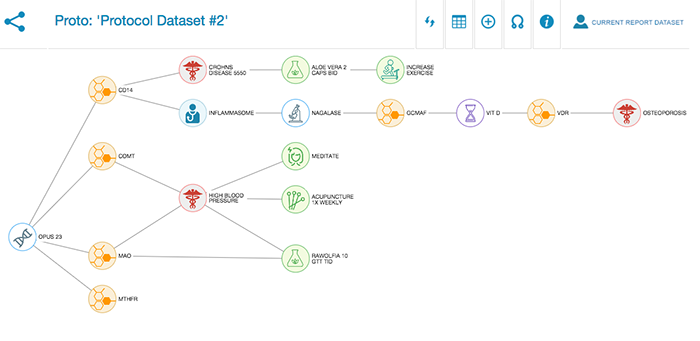
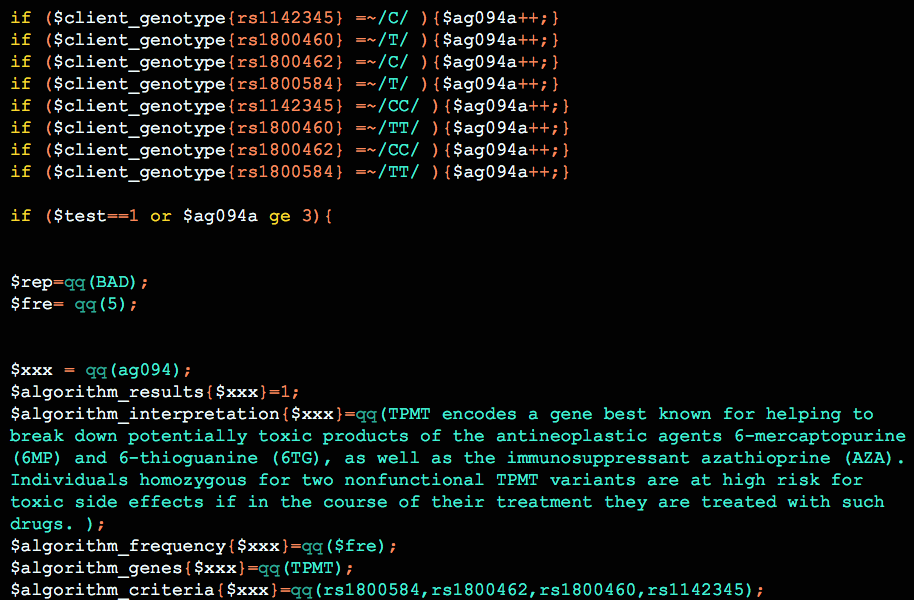
This is a current list of the multi-snp algorithms currently available in Opus 23. A few titles repeat, for the simple reason that two different algorithms, using different snps or genes, can result in a similar conclusion. Algorithms can be quite complex: it is not uncommon for one algorithm to […]
A Roster of Opus 23 Algorithms